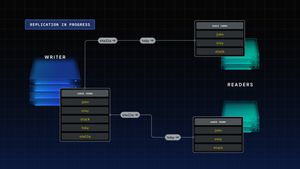
As we scaled our systems at Dyte, one of the first challenges we had to tackle was bottlenecking on the database layer. Simply put, our initial database design was far from optimal for the traffic that we wanted to serve, and we would consistently bottleneck our data layer whenever we saw a high load from clients joining meetings.
We have come a long way since then. With a complete redesign of our database schemas to power our v2 APIs, we got much better at handling the load on our data layer. Part of these changes was adding read replicas to our PostgreSQL database, however, this change came with its challenges.
Replication Lag
Replication is a strategy wherein database nodes used for reads are made distinct from those used for writes. In this way, read heavy traffic does not create a load on parts of the systems that require write intensive logic and vice-versa. This does introduce some eventual consistency- when a write happens, the writer node sends an update to readers asynchronously, and readers may take some time to catch up with the writer. This interval is called replication lag.
This is a typical consistency-availability tradeoff; by adding replication, you give up some consistency for higher availability. Many parts of your system will be unaffected by it, however, some parts might require strong consistency in order to function properly. The first step to creating a robust system that uses replication is to identify those parts.
Debugging Issues Caused By Replication
You’re highly unlikely to notice replication lag related issues during the course of development because, in your development environment, this lag is likely going to be too small to create any inconsistency in data reads. Of course, handling production traffic is a different story entirely. When your systems come under high-traffic load, replication lag can spike (and you should set up monitoring on your production systems so you’re aware when this happens).
So how do we debug replication lag related issues during development? One basic approach is to create a small testing server and perform a load test. This will push replication lag to a point where inconsistency-related bugs will become apparent. However, load tests themselves can be challenging to debug simply because of the volume of data that needs to be analyzed to check edge-case failures.
Another approach is to simulate this lag on the database level by deliberately introducing latency in your readers, catching up to writers, and testing normal flows out. In our case, we found that PostgreSQL allows for this by changing the recovery_min_apply_delay variable in PostgreSQL config.
Read After Write Consistency
Replication lag specifically creates issues with parts of your system that require read-after-write consistency - that is, reading a resource immediately after writing it to your database. If you’re doing simple CRUD-based operations, this is never much of an issue, but for compound operations, there might be cases in your code where read-after-write consistency is a requirement.
In our case, one such example was participant creation: once we write a participant to our database, a separate microservice requests a read immediately after and generates that participant’s auth token. On high replication lags, we started noticing that this create participant route was throwing 404s with participant not found errors.
Clearly, this part of the system requires read-after-write consistency- our auth token generation logic requires strong consistency of participant data for the create participant route to work correctly. In general, look for these patterns - if there is any place where your system reads a resource immediately creating it, chances are it will be affected by replication lag.
Mitigating Replication Lag
Mitigating the effects of replication lag is a solved problem. There are excellent references available online (see Shopify’s solution, for instance) on different approaches to providing read-after-write consistency wherever required. However, all of these approaches are very complex and we wanted to avoid over-engineering our systems just to deal with a small consistency issue.
The solution we came up with is a very simple read-through cache-based approach. First, we establish an upper bound on replication lag we can safely and reasonably maintain and set up alerts for violations of this upper bound.
Second, upon performing writes to our database, we also write the value to a decentralized cache; crucially, the time-to-live (TTL) for the value written to the cache will have to be greater than our replication lag upper bound established in step one.
We also maintain data consistency in the cache for updates and other operations. This ensures that the value is read from the cache is always correct.
In order to simplify the writing logic for this, we wrote our own caching wrapper library for Redis. The following code excerpt demonstrates how we mitigate replication lag using caching -
/**
Note the write to cache in the participant insertion method
**/
async writeParticipant(...) {
// Write participant to database
const storedParticipant = await this.insert(participantEntity);
// We put the resource in cache after creating it.
// This is done to compensate for unavailability of resource due to replication lag in DB.
// The expectation is that cache TTL > replication lag will always be true
await this.RepoCaches.Participant.set([meetingId, participantId], storedParticipant);
return storedParticipant;
}
/**
The decorator method on read participant checks if a value is set in cache using the specified keys
and only performs the db op if this value is not found in cache
**/
@RepoCaches.Participant.cacheFnResult({ keyVariables: ['meetingId', 'participantId'], ttl })
async readParticipant(meetingId: string, participantId: string) {
return this.createQueryBuilder('participant')
.where('participant.id=:participantId', { participantId })
.andWhere('participant.meetingId=:meetingId', { meetingId });
.getOne();
}
Conclusion
Replication is a useful strategy for scaling your database layer, but it can create bugs in your system that are non-trivial to deal with. We’ve looked at simple approaches to debug these issues and mitigate them should they arise. While there are other approaches to solving these problems, we like the simplicity of what we have implemented here. With this, you are now armed with some tools to help you live with replication lag in your systems!
I hope you found this post informative and engaging. If you have any thoughts or feedback, feel free to reach out to me on Twitter or LinkedIn. Stay tuned for more related blog posts in the future!




