Every engineering organization enjoys the challenges of scaling (ok not really 😅)! Yes, scaling can be difficult and challenging.
Everything that appears to be working properly in a system can fail at scale. Assume the replication lag is less than a second; but what happens when you bombard the system with 1000s of requests within a couple of seconds? The lag will increase!
Wait! Have you ever tried to build a WebRTC system that allows people to participate in a real-time audio-video call with no noticeable lag or delay regardless of where they connect from?
But first, some WebRTC 101.
Selective Forwarding Unit (SFU) Servers & Peer-to-Peer Network
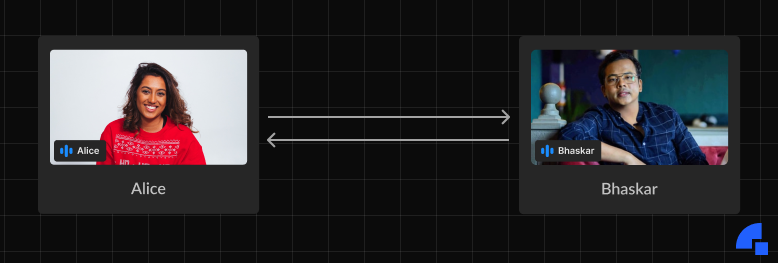
Assume Alice is in the United States and wishes to make a video call to Bhaskar in India. A bi-directional connection must be established between the two of them. Now in most basic form, they can just connect directly to each other.
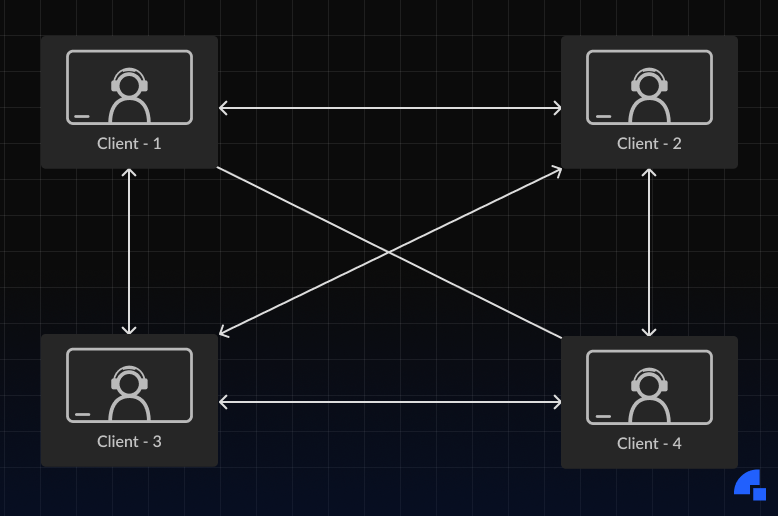
But that has a lot of caveats, mainly that it doesn't scale as the number of people in a call increases. Let's take a case where 4 people are in a call, every person would send their video streams to each of the 3 users. Also, it will purely depend on the network performance between the peers for the reliability of the call. In the current setup (peer-to-peer) the number of streams will increase exponentially with the increase in the number of people, which in turn will make the performance much worse with every additional user.
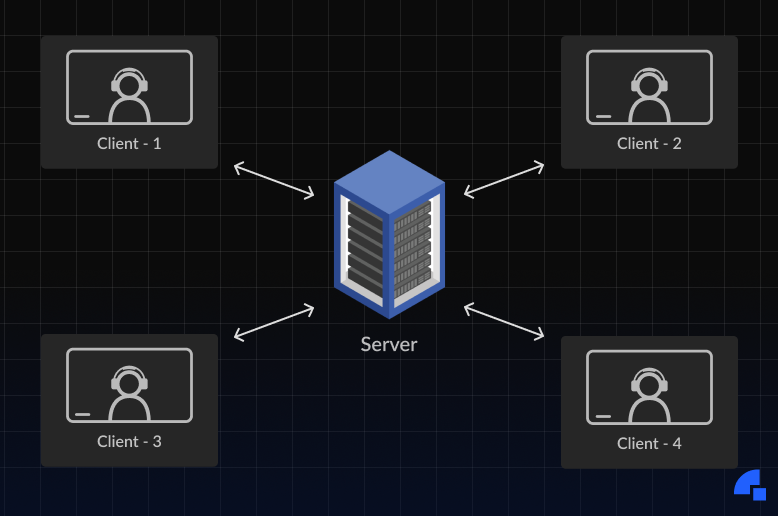
To solve the scalability and to improve the network performance of the call, we add a server in the middle of the network, connecting all clients directly to the server. This server is called an SFU or Selective Forwarding Unit. Now, each client is just sending their stream to the server and the server is further forwarding those streams to the client, thus reducing the congestion on the network which increases the call quality.
Going Beyond a Single Server
While the SFU architecture improves the reliability and scalability of the webRTC-based system, we started to encounter issues as we scaled to larger meetings and multiple sessions. There were primarily two issues:
- When we started beyond 200 people, we saw that the single server was unable to handle that load. We could scale the server to handle that load, but we couldn’t predict from the starting which meeting is going to cross that threshold. Moreover, we didn’t want to over-provision.
- All the people in a meeting always end up connected to a server in the Mumbai region which caused people who are connecting from regions far away from Mumbai (like the US) to have significantly degraded performance when compared to people who are nearby to the server.
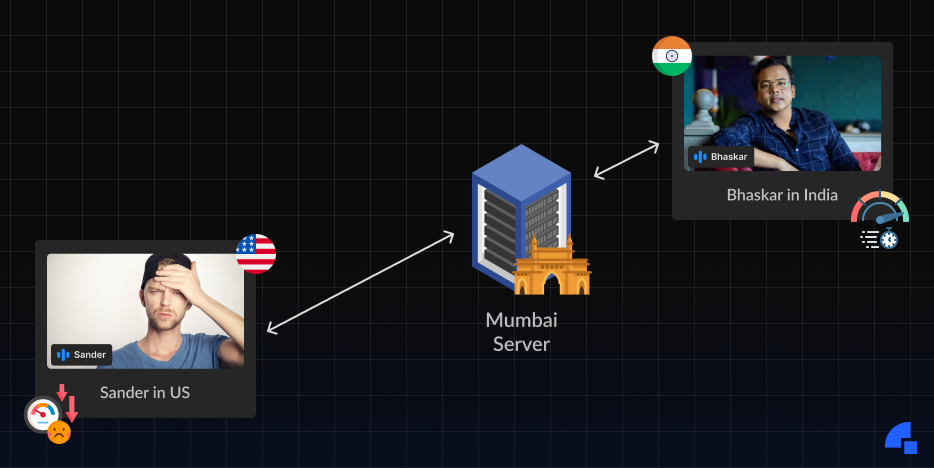
We knew how close the server is to the client impacts a lot on how the connection is (we all had played Battle Royale games 😉) but we realized the impact is much larger than we initially assumed it to be. There was a visible lag when talking to people in the US and though we can’t beat light (It takes around 300ms to reach from 2 points diametrically apart in, even some of our competitors claim to beat it), it was a lot larger than it should be.
For scaling, we tried to reduce the amount of CPU usage by making the codebase run blazingly fast, and we were able to reduce the CPU by 50%, but we were seeing the ceiling fast approaching as we were scaling. Multi-server was…

Decoding Multi-region Architecture
There are numerous ways to go wrong when building a server that spans multiple servers and geographies. Don't worry, we took care of everything.
The below diagram shows a high-level overview of what a multi-region looks like.
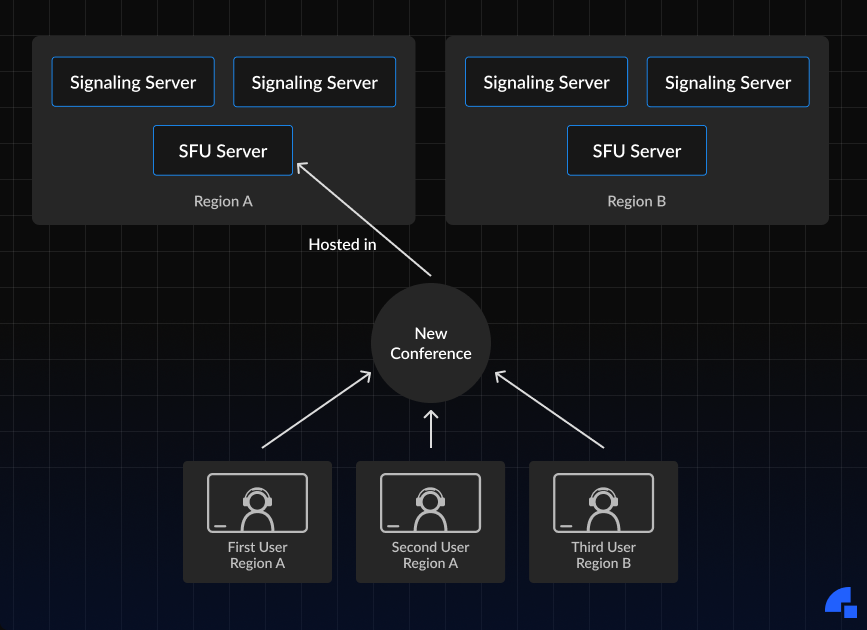
What Regions to Select for Multi-Region?
To select the best regions, we used the IP information collected by our pre-call test (which runs on the setup screen) to understand which regions we set up our clusters in. We started with US & SEA as the major hubs and further expanded to the EU as our client base scaled.
How did Dyte Expand from a Single Region to Multiple Regions Across the Globe?
At this point, it is fair to assume that you understand what multi-server and multi-region are and why we need them.
Let's take a closer look at how we achieved multi-region at Dyte. The way we implemented multi-region at Dyte differs significantly from that of many other organizations, such as AWS. Dyte is a WebRTC SDK provider, so we needed to handle media packets in a resilient manner.
When we say Dyte has multi-region deployment, we'd also like to highlight the capabilities we desired in our multi-region architecture:
- Traffic should be easily routed to various regions based on the client's geolocation.
- Any new region should be easily added and removed without affecting traffic.
To accomplish both of the aforementioned goals, we developed a new microservice called "Region Provider," which intelligently determines which region to connect respective clients to, based on their geo-location. A basic call flow is shown below.
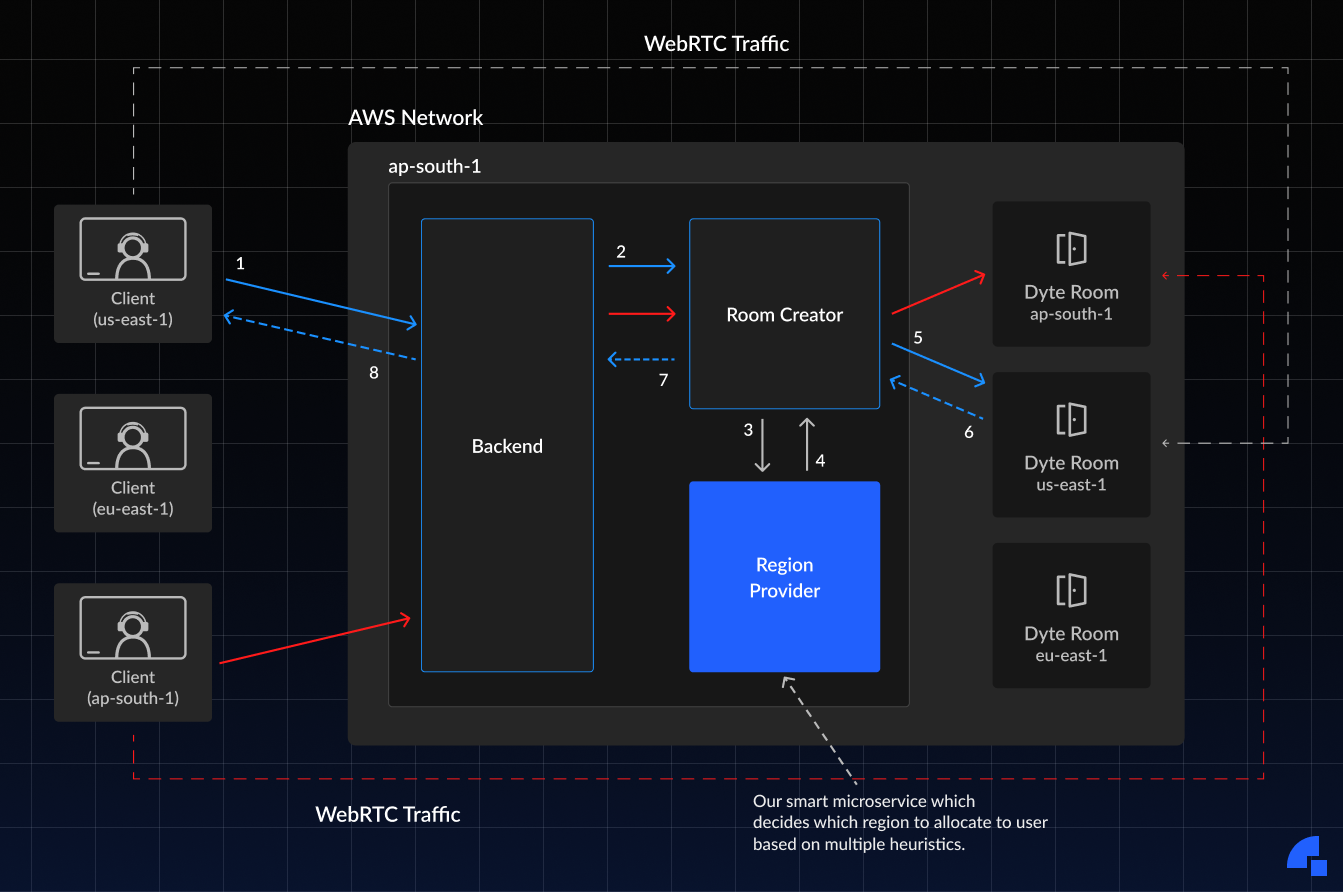
Now, I know this is a little intimidating at the first glance, but let’s go a little deeper and try to understand it better.
- A client who is in the
us-east-1region tries to join the room, it sends the API request to join the call. The request contains all the basic information to connect to a room along with the IPinformationof the user. - The backend which is running in
ap-south-1does some authentication for requests and calls the room manager service (or should we call it creator) service with all the IP information data. - The Room manager then calls our
region providermicroservice who is the key microservice in this architecture and does some magic on the IP information that it got with the request and finally decides the best suitable regions in sorted order of the highest priority. - Then the region provider sends back the top three best suitable regions for that user to the room manager.
- The room manager then pops the first element from the list of suitable regions that it got from the region provider and creates a meeting on that region.
- 6,7,8 points show that the response gets back to the client with all the necessary information to connect to the Dyte room of the region that it got assigned.
You can see the dotted lines with blue and orange colors, which indicates that after getting the region our client connects to the Dyte meeting running on that region.
There is another client with orange arrows, the same flow applies to that as well, as mentioned above.
If you are thinking about how the client got connected to that region or what it actually got in the response? Then we can’t tell you it’s super secret stuff.
……
……
Nah, I am joking it's very simple and straightforward, we just send the endpoint of the room running on the allocated region 😁 The client then connects to that endpoint over WebSocket, and voilà the client is in the room.
Region Provider (The heart of our Multi-Region Deployment)
The above explanation should make it clear that the region provider performs all of the magic that tells the client which region to connect to. It takes the IP information and calculates the nearest available region of the Dyte’s Meeting instance distance. Along with that, it calculates two more regions in order of least distance from the preferred region. In case any failure happens in the preferred region, the client can connect to the 2nd and 3rd most preferred regions. This setup makes Dyte’s call highly available and super resilient. Additionally, we have flags in our meeting room manager to forcefully assign a client to a specific region. This flexibility helps us with the “Routing of traffic”.
“The addition and removal of regions” are also taken care of by the region provider we just need to call a molecular action (If you haven’t read about how we use Moleculer at Dyte, please check this out https://dyte.io/blog/how-moleculerjs-powers-dyte/) and provides the information about the new region, and it registers that region to the database. Then we deploy the Autoscaler service. Yes, we have our own Autoscaler service to manage the nodes where meeting happens, Although we use Kubernetes heavily, still we don’t use HPA for our meeting nodes. We already have a blog on how our Autoscaler microservice intelligently handles the traffic by Sagar Rakshe, visit https://dyte.io/blog/load-prediction-autoscaler-dyte/. We deploy the Autoscaler service in that new region and the Autoscaler service scales up our meeting nodes.
To remove a region, we need to first clean up all the resources that are created in that region, then we call a Moleculer action which removes the region entry from the database, and thus no further calls can go to the removed region.
This is how we get high flexibility and more control over the traffic, along with resiliency and low latency call. Because now the clients can connect to their nearest node for meeting and since we run multiple nodes on multiple regions, there is no downtime even if any region goes down we can still serve the traffic. These capabilities of our system make Dyte a leading SDK provider with low latency and high resilience in WebRTC.
At Dyte, we use multi-region not just for scaling and low latency but for also other use-cases that help the product experience become 10x better! Curious to know? Wait for our upcoming articles, we will definitely share them.
Already mesmerized and can’t wait 😵💫? Apply for open roles in our job portal. We always welcome people who are passionate about more than just remote work, cool offices, or coffee machines. Join us and let’s build the ‘Dyte Culture’ together.




