
WebSockets play an integral role in powering meetings at Dyte. From initial WebRTC negotiation to supporting real-time collaborative functionalities in a meeting, everything runs over WebSockets. As we started scaling our meeting size, we saw many WebSocket disconnections, which in turn created failed WebRTC negotiations and other basic functionalities. Scaling WebSocket is not as easy as just adding more servers to your backend, it requires some specific architecture and infrastructure requirements that we'll be going through in this article.
But before anything, let's understand a bit about WebSockets.
What are WebSockets?
WebSocket is a bi-directional communication protocol built over TCP, which allows client and server to communicate in a message-oriented way with less overhead. This connection established between client and server is long-lived, i.e., it is kept open as long as it's needed. A usual WebSocket connection has the following lifecycle.
- The client sends a connection upgrade request via HTTP.
- The server takes this request and converts the underlying TCP connection to a WebSocket protocol.
- Messages are exchanged between the client and server over this connection until one of them sends a close message(that terminates this connection).
It is one of the few networking primitives available inside a browser context, often making it the only solution for real-time communication needs.
WebSocket is your go-to protocol if your application needs any kind of real-time update with less latency and delay.
Why are WebSockets hard to scale?
To understand the challenges faced while scaling WebSockets, let us first list down some limitations associated with WebSockets.
- Per-connection memory overhead - WebSocket connections are long-lived and hence stateful in nature. The memory usage includes memory for the connection object and buffers for sending/receiving messages. The total amount of memory required can be significant if you have many concurrent WebSocket connections.
- File descriptors: Every TCP connection uses a file descriptor. Operating systems limit the number of file descriptors that can be opened at once, and each running process may also have a limit. When you have a large number of open TCP connections, you may run into these limits, that can cause new connections to be rejected or other issues.
- CPU usage: WebSocket connection needs mechanisms to detect active and stale connections. For example, the server needs to periodically send and receive TCP keepalive messages to check whether the connection is still alive. Also, any data sent or received on the connection needs to be processed.
- Bandwidth: TCP connections consume a small amount of network bandwidth even when they are idle due to the transmission of TCP keepalive messages and other control messages.
- Message size: WebSocket messages can theoretically be of any size (up to a limit set by the WebSocket protocol). If your application sends or receives very large messages, this can consume a significant amount of memory, particularly if many such messages are being processed concurrently.
Most of the above limitations are per machine, and therefore, if we just add more machines, you have solved it, right? Not that easy.
Take for example, our Livestreaming SDK product, the problem with having 100K people in a session isn't just making 100K socket connections. It is also about maintaining a consistent state between the 100K people.
Scaling stateful systems in a horizontal and robust manner is always hard, and so is the case with WebSocket servers.
A general idea used to scale stateful systems is to add an inter-communication layer between these components to ensure resource consistency. Adding one more communication layer on top often creates challenges in terms of handling high throughput of messages, ensuring consistent execution of concurrent events, and fault tolerance in case of service unavailability.
But don't worry. In this article, we'll explore some recipes that we use at Dyte to scale WebSockets to millions.
Scaling WebSockets beyond a single machine
When we are talking about millions of network connections we need a way to distribute these connections across multiple servers running over multiple machines. As soon as you start distributing these connections over multiple machines, you need a way to deliver a message received by a particular server to all others too. A simple way is to just broadcast it to all server instances, but this would create a lot of overhead and resource utilisation. Here's where the message broker comes into the picture. It allows the routing of messages based on certain identifiers and helps effectively distribute the message load using queues.
There are many message brokers that are suitable for this task, e.g. Rabbitmq, Kafka, Nats, etc. While you choose yours keep these things in mind -
- Suitable to handle and create millions of topics.
- Maintain message order in respective topics.
- Easily able to scale and handle large numbers of queues.
Using a message broker, however, does not solve the major issue of maintaining a consistent state between multiple servers.
Network optimisations
Handling a million connections means processing millions of messages. To efficiently do this we need some optimisations. Using protobuf to serialize and deserialize our messages can be effective.
- This gives us a 40% smaller message payload over JSON.
- Provides an automated way to handle API contracts between client and server.
- Faster encoding and decoding times.
Another network optimisation that helps us process large numbers of messages in large meetings is batching i.e. sending multiple messages over a single network call. This not only prevents excess system calls but also reduces latency that would have been caused due to repetitive network calls.
Tuning the underlying OS
Every connection opened, costs us a file descriptor, and since each WebSocket connection is long-lived, as soon you start to scale, you will get error's like too many files open. This gets raised due OS limit on the max number of file descriptors which is generally 256-1024 by default. So you want more connection? Make this limit higher.
You can simply set the max limit of opened file descriptors for your OS with the following command -
ulimit -Ha
But this changes the ulimit only for that particular process, to change it permanently for the machine, you can update it here /etc/security/limits.conf. Check this for the complete guide.
But let us explore a slightly elegant approach to do this. Nowadays, everything runs as docker containers that are scheduled over a pool of nodes in a cluster. So configuring these nodes manually is an overhead task. We can automate this optimisation within our application, by making a system call to increase the file descriptor limit. Below is a reference to the Golang snippet that we use to optimise our cluster nodes before our application boots up.
if runtime.GOOS == "linux" {
var rLimit syscall.Rlimit
if err := syscall.Getrlimit(syscall.RLIMIT_NOFILE, &rLimit); err != nil {
logger.Fatalf("failed to get rlimit: %v", err)
}
rLimit.Cur = rLimit.Max
if err := syscall.Setrlimit(syscall.RLIMIT_NOFILE, &rLimit); err != nil {
logger.Fatalf("failed to set rlimit: %v", err)
}
logger.Info("Increased system ulimit")
}
Using long polling
There could be a number of reasons that your client is not able to connect using WebSocket.
- They may not have a stable internet connection.
- Their browser/device might not support WebSocket API.
- They might be using a proxy/firewall system that blocks or doesn't allow WebSocket transport.
To provide a smooth and uninterrupted user experience having fallback transports like long polling can help. Additionally, having long polling as a transport provides a lot of visibility in tracking connection lifecycle, which might be difficult to do with only WebSockets.
Building a robust reconnection and message re-queueing system
One more problem that is unique to WebSockets in contrast to HTTP is the need to have a reconnection and re-queueing system. There could be multiple reasons that could result in a WebSocket disconnection, but as soon as a disconnection happens, your client needs to handle two things.
First is to start the reconnection process to a server, and second is to store the messages in a message buffer until the connection is re-established and ready to be used to send those queued messages again. This will ensure a robust and smooth experience for the user. However, note that in the case where your server is handling millions of connections and all connections get dropped during a deployment or any resource outage, this will cause a massive surge of reconnects, which can impact your system. To handle this surge safely, make sure to add an exponential backoff to your reconnection logic.
Maintaining consistent state
Maintaining a consistent state in a distributed system is hard. There are multiple techniques that depend on your use case and data movement patterns.
Concurrency control: In a multi-user application, concurrent operations on a shared state can lead to inconsistencies. Techniques like locking, optimistic concurrency control, and using atomic operations can help manage this.
Immutable data: Using immutable data structures can help avoid many concurrency-related issues. When data is immutable, you don't need to worry about it being changed by another part of the system while you're working with it.
Event sourcing: This is a design pattern where changes to the application state are stored as a sequence of events. These events can be replayed to reconstruct the current state. This makes it easy to understand the history of an object and reconcile any discrepancies.
Idempotent operations: Making your operations idempotent means they can be safely retried without changing the result beyond the initial application. This can be helpful where operations may occasionally fail or be duplicated.
Example: Whenever a host mutes a participant in a Dyte call, it will be an idempotent operation if we can send a “mute” event instead of a “toggleAudioState” event
Compensation actions: In distributed systems, where a series of operations might span multiple services, it's important to design compensation actions that can be taken if any step in the process fails. This can help ensure system-wide consistency.
Apart from these, you can use data structures like Conflict-free Replicated Data Types (CRDTs), which are specifically designed to handle concurrent operations in a way that can be automatically reconciled.
Bringing it all together at Dyte
The WebSocket layer at Dyte consists of 3 layers, called edge, message broker, and hub. A high level overview of how these layers interact with each other is
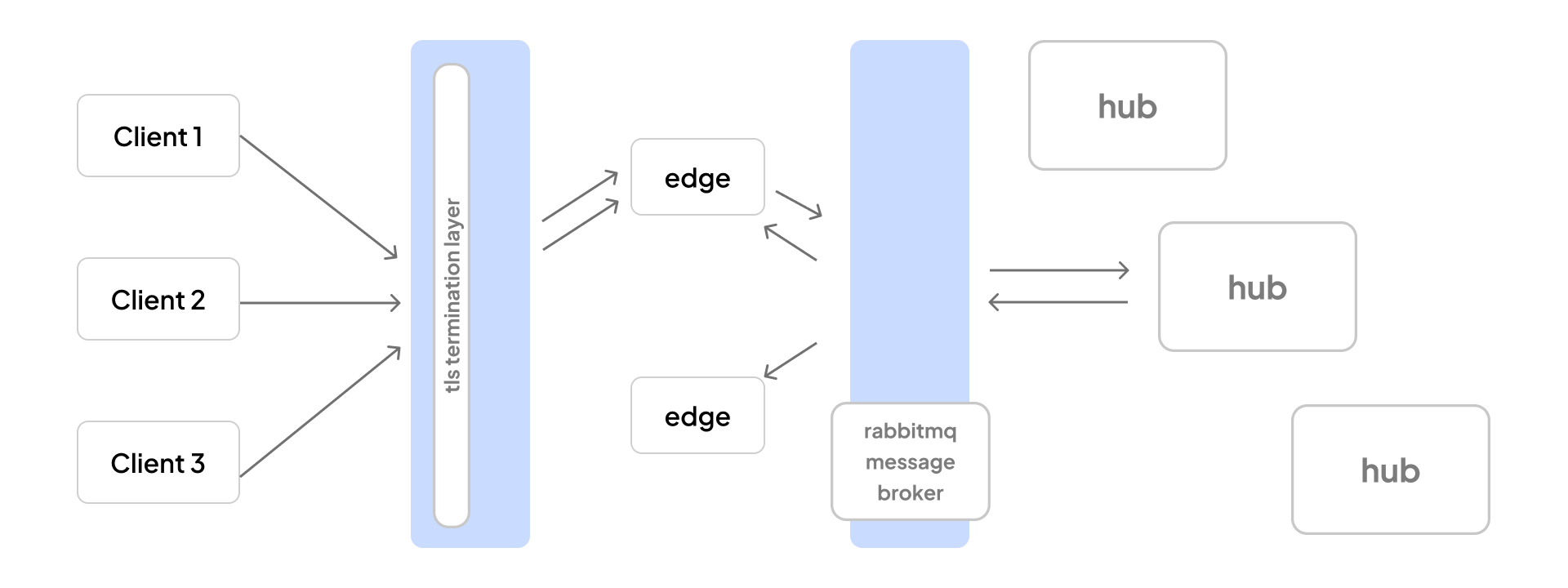
- Edge is responsible for maintaining WebSocket connections with clients, and communicating with the message broker to send/receive messages to the hub. All edge servers sit behind a load balancer that distributes connections among available backends.
- The message broker is responsible for routing messages between the edge and the hub. In our case, we rely on
rabbitmqas our messaging system. - Hub is responsible for processing the message and broadcasting it to the required WebSocket connection.
In addition to this, some of the design and infrastructure decisions that have made scaling our system easy are
- Limiting responsibility of our edge layer to only handle WebSocket connection and relay those messages. It helps us keep our edge layer light and scale it rapidly in time of increasing load.
- Handling TLS termination separately from our application layer. TLS terminations are a CPU intensive task. That's why we prefer handling it at our load balancer layer. This not only makes scaling the edge layer easy but also provides a consistent and easy way to manage security at a global scale
That's it! Take your system, break them into an edge and hub, add an efficient pub/sub layer, optimise payload size, use OS optimisations for garnish, and there's your recipe to scale WebSockets.
Hope this article helps you build more scalable and robust Websocket systems. Stay tuned for such more articles on WebSockets. If you have questions or have feedback about this blog, feel free to reach out to me on LinkedIn.
If you haven't heard about Dyte yet, head over to dyte.io to learn how we are revolutionizing communication through our SDKs and libraries and how you can get started quickly on your 10,000 free minutes, which renew every month. You can reach us at support@dyte.io or ask our developer community if you have any questions.




