What is Track-based recording? Wait, didn’t we already do recordings?
It is but yet another term in the whole WebRTC and recording space. Fear not, as your Friendly Neighborhood Engineer is here to explain.
Unlike traditional recording methods that might capture entire session with multiple participants and other elements as singular files, track-based recording isolates and processes audio and video streams separately.
But before we get to that part, let's address a few whys and hows.
Why do track-based recording?
Because we can. (quite literally!)
The default recording option at Dyte is browser-based recording setup. A Chromium instance in our server screen records all videos rendered on a webpage. Being browser-based, it can also record whiteboards and other non-media stuff. Given all that, track-based recording takes things to a whole other level — or, well, multiple separate levels.
Recording individual tracks gives you a lot of flexibility and tinkering capabilities:
- Separate audio and video tracks: Separately recording each participant's audio and video enables customized post-production edits.
- High-quality streams: When you record the track directly, you get very high-quality individual tracks directly from the producer without any compression that you might see in a browser-based approach which basically captures the screen and transcodes it.
- Ease of synchronization: Recording audio and video tracks independently facilitates better A/V sync. This is essential to preserve the conversation's organic flow and guarantee that the audio and visuals are in sync throughout the video conversation.
- Flexibility for future use: When the tracks are independent, the recording can be used more easily. For example, you could wish to record two versions of the video chat, one with everyone in it and the other concentrating on a particular topic. When the tracks are distinct, you can quickly remove and merge the necessary portions. High-quality streams could also be composited into any layout or resolution for high-quality video production events.
How do we do track-based recordings at Dyte?
All the calls running on Dyte for track-based recording are handled on our in-house PION based SFU server. It allows us to do a lot of cool things, one of which is getting access to the raw tracks of all the participants in the call.
Our SFU forwards all the RTP packets directly to our recording media server streamline for processing. It also forwards events like mute/unmute, device change, and RTCP feedback. The server tags all the packets with accurate meta information to distinguish between different participants' tracks.
Streamline: Media server
Processing all the RTP streams, compositing, transcoding, and delivering them is no trifling affair. And so, GStreamer comes into the picture.
GStreamer is a multimedia framework designed to handle a wide range of tasks — from simple video playback and audio/video streaming to more complex operations such as audio mixing and non-linear video editing.
It has a collection of plugins that you can join — pretty much like Legos — and build up a whole media pipeline. Whatever you could possibly think of, with an audio, video, or a timed data track, you will probably find a plugin for that. And if not, you can build your own on top of some basic primitives.
While most of the GStreamer is written in C, Rust is being adopted very heavily by the team. All the new plugins are mostly written in Rust. It has bindings for almost all popular languages like Java, Golang, Python, Ruby, etc.
A few basic GStreamer-specific terms:
- Element: It is the basic building block for a media pipeline. You could simply imagine it as a black box where you put in data, it does some voodoo magic, and you get output data. Say, for a decoder element, you'd put in encoded data, and the element would output the decoded data.
- Pipeline: All GStreamer elements must typically be contained inside a pipeline before they can be used, as the pipeline takes care of some clocking and messaging functions.
- Bin: Bin is nothing but a collection of elements linked together. Bin itself is also an element, so it can be used in all the same places an element can be used. And yes, a pipeline is just a glorified Bin.
- Pad: Pads are elements that interface with the outside world. They serve as the link points between elements. They are extremely lightweight and are used to facilitate data flow within a pipeline. Based on their direction, they are categorized into two main types: source pads and sink pads. Source pads are responsible for generating data, while sink pads consume data.
- Buffers and events: The data flowing through a pipeline consists of a combination of buffers and events. Buffers contain the actual media data. Events contain control information, such as seeking information and end-of-stream notifiers.
Luckily for us, GStreamer provides a lot of elements out of the box to build a processing pipeline. We used a combination of rtpbin, rtpopusdepay, rtpvp8depay, and webmmux with some basic elements like tee, queues, and audio/video decoder to build it. An advanced overview of it looks something like the following.
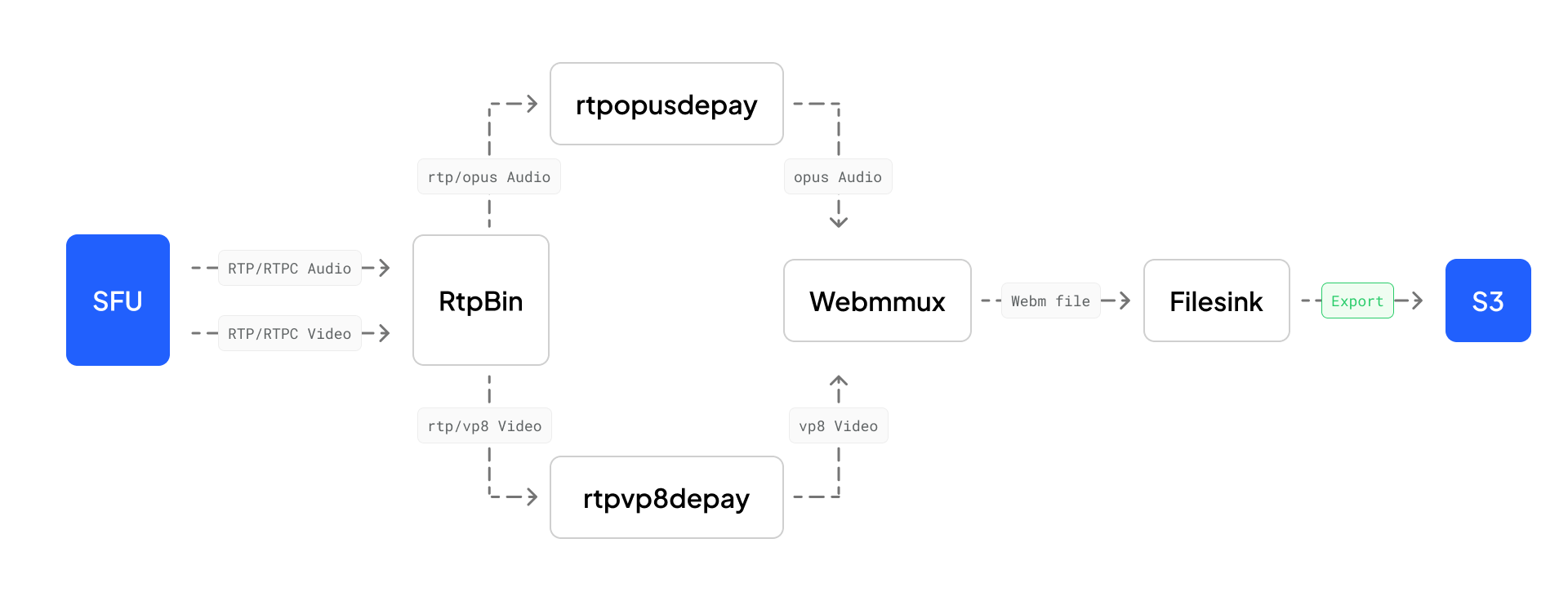
Let’s talk about all the elements used in a bit more detail:
- rtpbin: This does most of the heavy lifting for the rtp stack. It contains multiple elements like
rtpsessionit couples together RTP and RTCP for a participant for both sending and receiving,rtpssrcdemuxit acts as a demuxer for RTP packets based on the SSRC of the packets. It lets you easily receive and decode an RTP stream with multiple SSRCs.rtpjitterbufferit reorders and removes duplicate RTP packets. It can also detect packet loss and send the event down the application to be handled,rtpptdemuxit acts as a demuxer for RTP packets based on the payload type of the packets. - rtpopusdepay: This is responsible for extracting opus data from the RTP packets. It follows the RFC 7587 for extracting data.
- rtpvp8depay: This is responsible for extracting vp8 data from the RTP packets. It follows the RFC 7741 for extracting data.
- webmux: This is responsible for muxing both audio and video into a
.webmfile. There are multiple properties we can configure to change the behavior of muxer. example:offset-to-zeroThis makes sure the new file always starts from 0 instead of the pipeline playing time.streamableThis is used to define if the sink is streamable or not. In layman's terms, you can think of it as if we can seek the sink for writing headers and stuff.filesinksought is one such element that can be seeked. - filesink: Write incoming data to a file in the local file system. You can set the
locationproperty to specify the file path.
Our service is built so that it's easy to add any ingress and egress point. Want to add RTMP out as a source? No problem; just attach another bin. Want to get data directly from the client? No issues; here’s an ingress bin. GStreamer has truly helped us build the most generic and modular pipeline we could imagine.
Our language of choice for this service was Rust. This was a new language for our team and, well, the company. So, it had all the gotchas of introducing a new language into the company attached to it, like rebuilding internal tooling, training everyone to a certain point where they are okay contributing to the project, and —let’s not forget — Rust does have a steep learning curve.
Then why did we go with it? One of the driving decisions was Rust being officially supported by the GStreamer team. So we knew if we had to write our own elements or custom logic, it was either Rust or C. I would pick Rust over C any day (that might change someday, but today's not that day). Plus, we wanted to push these servers to their absolute limit and have full control over all the parts of the pipeline.
Throughout the development process, we took on the challenge of creating some of our own custom elements. This allowed us to tailor our system to cater to specific needs and functionalities that were not readily available. It also enhanced our understanding and control of the internal workings of GStreamer.
While it may all seem perfect from afar, GStreamer had its own quirks, which were sometimes very annoying to debug:
RtpBin: While rtpbin is a great package of elements that does most of the heavy lifting, it has its own way of doing things. It has a non-spec-compliant way of handling RTP and RTCP packet parsing. If you send an RTCP packet first for a track (the correct term is a session from rtpbin’s perspective), it just fails to handle the incoming RTP packets.
EOS events: EOS events lets all the elements know that they should flush the buffer and start with the cleanup. At least, that's how I understand it. It gets propagated to all the downstream elements in the pipeline, and finally, when it reaches a sink element (an element that only has a sink pad and no source pad, like filesink or udpsink), it reports it on the pipeline bus. Now, different elements, as well as bins, handle this differently. Bin collects all the EOS messages before posting them to its parent. The documentation on this feels a little incomplete.
Luckily, it comes packed with the tools to debug your program. We also wrote a simple mocker using GStreamer itself, which helps us avoid the SFU side of things and test individual components of the server. The mocker allocates resources like users and recordings using the streamline API and starts sending audio and video RTP packets.
This helped us a lot while building the application and writing some end-to-end tests. Coming back to things that GStreamer gives us:
- You can get very granular with the logs and forward them to a file.
- You can get a live view of the GStreamer pipeline using (add the code snippet). We have an internal endpoint that we can hit at any time to get the SVG output of the whole pipeline. It helped us debug certain edge cases on prod.
What's next?
While we have an initial version of our media pipeline that facilitates track-based recording and powers our AI services, it still has a long way to go.
We are working on composite grid-based recording on streamline itself. From our initial testing, it uses up fewer resources than a traditional browser-based recording to do the same amount of work.
Multiple encoding for a recording? Sure, why not? MCU-based calls? Maybe. The possibilities are seemingly endless. We are also exploring offloading some of the encoding and decoding work of streamline to machines equipped with media accelerator cards. We already have the building blocks, and we can only go further from here.
Let us know if you have any use cases for this, and we will be happy to assist! If you want to know more, here's the link to the documentation.
We hope you found this post informative and engaging. If you have any thoughts or feedback, please reach out to us on LinkedIn and Twitter.
Stay tuned for more related blog posts in the future!
If you haven't heard about Dyte yet, head over to dyte.io to learn how we are revolutionizing communication through our SDKs and libraries and how you can get started quickly on your 10,000 free minutes, which renew every month. If you have any questions, you can reach us at support@dyte.io or ask our developer community.




