When we started with Dyte, we built the SDK that could accommodate minimal UI changes and soon we felt the urge to be more flexible. Our newer SDKs provide that flexibility. You can design virtually anything using our reusable components. However, we feel that even this much is not good enough for us, we want to give the power of customization to the ones who need it most: Developers.
To facilitate the customization, Dyte has provided easy-to-use plugins and ways to create them from Day 1 (Day 0 for developers). With plugins and reusable pluggable components, developers can build the UX they want in their apps or on their websites.
The latest SDKs provide flexibility not just in terms of the UI but in terms of media as well. Exposing APIs to alter audio/video on the fly does open pandora's box of possibilities for developers.
One such case is speech-to-text. Live conversion of the ongoing conversation into text can help people, with hearing impairment, and can aid non-native speakers.
There are many third-party APIs to convert speech to text (aka Audio Transcriptions) such as Symbl.ai and Google Cloud Speech API.
A client's requirements may differ from another. As Dyte is vendor agnostic, we don't want to force our clients to use a specific service. Therefore, by exposing raw audio and a way to manipulate it on the fly, we can provide a way for developers to integrate such parties, on their own thus giving them the ability to customize it even further.
Transcription using Streams API
Another case is when developers want to plug their own audio/video filters similar to Snapchat filters and Talking Tom filter. Maybe you want to give a retro look to all video participants? Maybe a special happy birthday filter? Maybe funny hats? Maybe a Darth Vader pitch to welcome people to the dark side?
All of this is possible now, using our new group of APIs: Streams APIs.
We aim to expose audio/video streams to developers and to give abstractions on top of that so that you don’t have to be a WebRTC pro to play with stream APIs.
To interact with Video Streams APIs, all that developers need is an understanding of some basic JavaScript and a little bit of Canvas expertise. For example, adding a retro theme to meeting participants is as simple as writing the following piece of code.
function RetroTheme() {
return (canvas, ctx) => {
ctx.filter = 'grayscale(1)';
ctx.shadowColor = '#000';
ctx.shadowBlur = 20;
ctx.lineWidth = 50;
ctx.strokeStyle = '#000';
ctx.strokeRect(0, 0, canvas.width, canvas.height);
};
}
A code block for Retro Theme using Streams API
That’s all.
We call such small pluggable functions, the middlewares. Dyte supports on-the-fly changes for both Audio & Video streams.
This guide will take you through the steps and the APIs which will help you plug such middlewares and will guide you on how you can create your own as well.
So let’s start.
How to add or remove a video middleware?
We, at Dyte, believe in giving the simplest of APIs to the developers so they don’t have to spend a lot of time going through the documentation and making sure that everything is in place.
We wanted a very simple API to add/remove middleware so we created one (or two).
// Add video middleware
await meeting.self.addVideoMiddleware(RetroTheme);
// Once done, In a later section, Remove video middleware
await meeting.self.removeVideoMiddleware(RetroTheme);
// You can also remove all video middlewares together
await meeting.self.removeAllVideoMiddlewares();
A code block for video middleware using Streams API
The above code snippets show you how to add and remove a middleware. Basically, we have exposed 2 APIs to add and remove video middleware on meeting.self. All these APIs need is the middleware function. In this case: RetroTheme.
How to add or remove an audio middleware?
APIs to add or remove audio middleware are similar to video middleware.
// Add audio middleware
await meeting.self.addAudioMiddleware(YourAudioMiddleware);
// Once done, In a later section, Remove audio middleware
await meeting.self.removeAudioMiddleware(YourAudioMiddleware);
// You can also remove all audio middlewares together
await meeting.self.removeAllAudioMiddlewares();
A code block for audio middleware using Streams API
How does a video middleware work?
At Dyte, we use WebRTC to power our meetings. Once a user turns on their video camera, and provides us permission, we capture the video stream from it. As a developer, you can now access these streams and tracks programmatically.
//Somewhere in your codebase
const meeting = await DyteClient.init(...);
// You can get the video track which everybody will see if your camera is turned on
meeting.self.videoTrack()
// You can also get raw video track
meeting.self.rawVideoTrack();
A code block for accessing Streams
Once the camera is turned on, we get the participant's video feed/stream. Developers can use this stream to alter it on the fly to add their own filters, before sending it over to other participants. However, this is tricky and requires WebRTC fundamental knowledge. Therefore, Dyte takes the complexity out by providing abstraction on top of this.
To understand what we do, one must understand that a video is nothing but a collection of a lot of pictures (frames in technical terms) being rendered on a screen very fast, subsequently. Starting from 20-30 times per second up to 120 times per second for some screens, thus giving us an illusion of a moving object/person.
We wanted to give direct access to these frames to the developers so that they can do whatever they want with each frame. To do so, we needed a canvas to draw every frame and to hand it over to the developers.
We read the camera feed, draw the raw frame on canvas, then give this canvas and context to the first video middleware. First video middleware then alters the canvas however it likes. Now this altered canvas gets sent to the next middleware and so on. Basically, we pipe the resultant canvas to the next middleware.
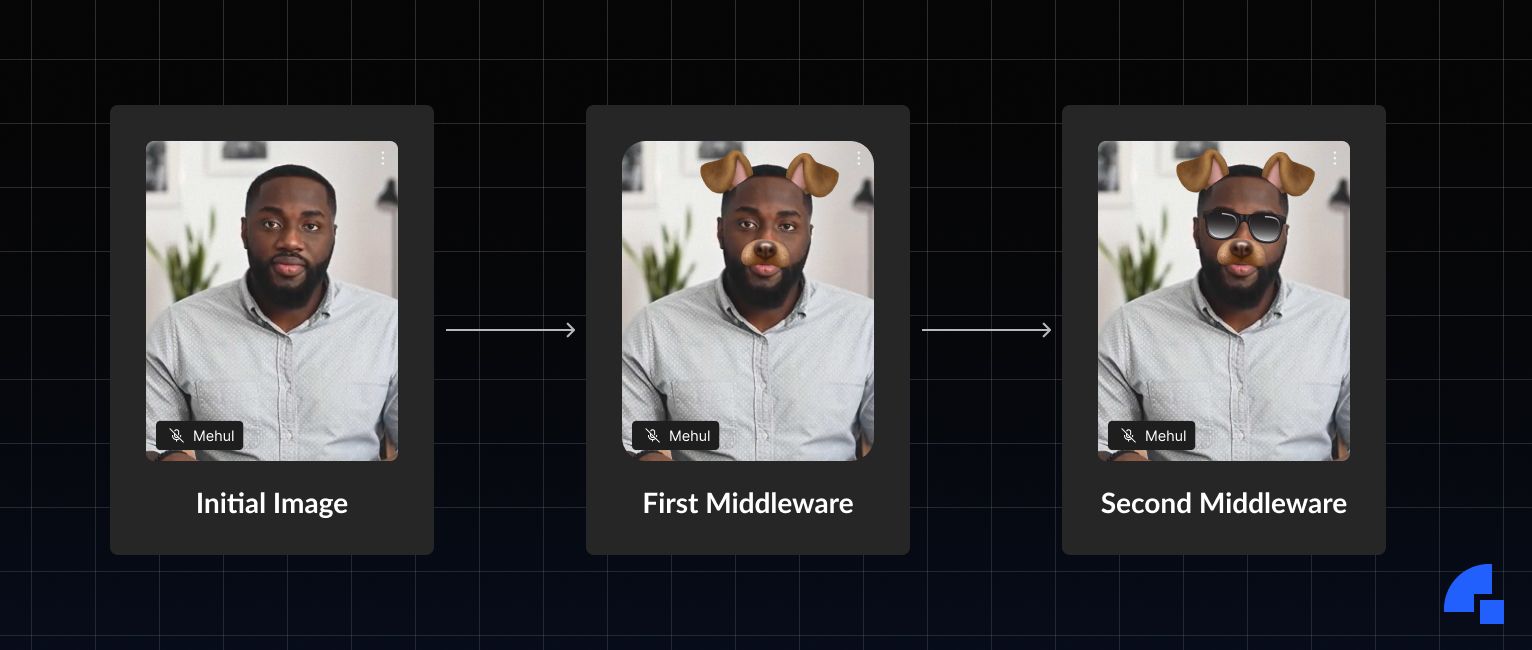
But this brought us to 3 challenges.
- How do we give the flexibility to add middlewares on-the-fly or way before enabling the mic/camera?
- How many times a second should a middleware get called to give the non-flickering effect? How to achieve this in a background tab?
- What if the developers want to have one-time calculations (fetching AI/ML models)? What if developers want to track the position of an item throughout a video by comparing it to the last picture?
We solved the first challenge by designing Dyte SDK in such a way that you can even add a middleware way before the actual use. You can even add it on-the-fly, it will immediately take effect if the user has a mic/camera turned on. Despite adding a middleware, A middleware won’t be executed unless the user turns the camera/mic on.
The second challenge was the most complicated one, solutions such as Window.requestAnimationFrame & setInterval didn't work for background tabs on browsers & operating systems having different power-saving mechanisms.
There was a promising solution that Chrome gave - Insertable streams. However, that would only work in the latest chromium-based browsers, and writing a polyfill quickly was nearly impossible. Safari had very strict power-saving policies and we were fine with not giving Safari support in initial releases. However, we didn't want to miss out on this feature for Firefox. So we had to look for another solution.
We solved the second challenge by using worker threads. We are periodically calling the middlewares giving developers enough room for their filter processing.
There are various kinds of machines (Macs / PCs / Tablets) available, some more powerful & liberal whereas others are less powerful & stingy. Therefore, in the next phase, we will introduce a variable frame rate based on the device capabilities of end-users.
We solved the third challenge by defining the structure of middleware. We expect users to provide a function that returns a function when called thus utilizing closures. You can learn more about closures here.
/*
YourMiddleware can be an async function as well.
We support async as well as normal functions
*/
async function YourMiddleware(){
console.log('this will be called only once when you turn on the video');
// Put your async-await API calls AI/ML model fetch here.
/*
Returned function (having canvas, ctx as params) can be an async function as well.
We support async as well as normal functions.
*/
return async (canvas, ctx) => {
console.log('this will be called 20 - 30 times per second');
}
}
Middleware structure
We call middleware’s outer function only when you turn the video on. If a video is turned off and turned back on, the middleware will get called again. Whereas the lambda function that is being returned can be called 20 - 120 times per second, based on Machine capability if the user video feed is on. If the user has turned off his/her camera, we would no longer be calling the returned function.
You can add all your AI/ML model fetch or any sort of stateful variables (for tracking details from the previous picture) in the outer function.
A complete working solution would be something like:
//Somewhere in your codebase
const meeting = await DyteClient.init(...);
function RetroTheme() {
console.log('Initialising RetroTheme');
return (canvas, ctx) => {
ctx.filter = 'grayscale(1)';
ctx.shadowColor = '#000';
ctx.shadowBlur = 20;
ctx.lineWidth = 50;
ctx.strokeStyle = '#000';
ctx.strokeRect(0, 0, canvas.width, canvas.height);
};
}
// Add video middleware
meeting.self.addVideoMiddleware(RetroTheme);
Complete middleware implementation
How does an audio middleware work?
Audio middleware has a slightly different structure and internal working.
Audio is nowhere similar to Video when it comes to composition. Therefore, it requires a different way of handling it.
For videos, we gave the canvas to the developers to let them paint on it. In a similar fashion, we provide audio context to the audio middleware.
If this doesn’t suffice, developers can even use raw or altered audio streams.
//Somewhere in your codebase
const meeting = await DyteClient.init(...);
// You can get the audio track which everybody will hear if your mic is turned on
meeting.self.audioTrack()
// You can also get raw audio track
meeting.self.rawAudioTrack();
A code block to retrieve audio track
Similar to the video stream’s canvas, we pass the audioContext around, and developers work on top of the response from the previous audio middleware. It is piped in a similar fashion to the video stream’s canvas.
Audio can be altered using ScriptProcessor and AudioWorkletProcessor . We support both ways of performing audio alterations.
Audio Middlewares are simple/async functions that are expected to return AudioWorkletNode or ScriptProcessorNode.
Sample Audio Middleware integrations:
//Somewhere in your codebase
const meeting = await DyteClient.init(...);
async function addWhiteNoise(audioContext) {
const moduleScript = `
class WhiteNoiseProcessor extends AudioWorkletProcessor {
process (inputs, outputs, parameters) {
const output = outputs[0]
output.forEach(channel => {
for (let i = 0; i < channel.length; i++) {
channel[i] = Math.random() * 1.0 - 0.5
}
})
return true
}
}
registerProcessor('white-noise-processor', WhiteNoiseProcessor);
`;
const scriptUrl = URL.createObjectURL(new Blob([moduleScript], { type: 'text/javascript' }));
await audioContext.audioWorklet.addModule(scriptUrl);
const whiteNoise = new AudioWorkletNode(audioContext, 'white-noise-processor');
return whiteNoise;
}
// Add audio middleware
meeting.self.addAudioMiddleware(addWhiteNoise);
Sample audio middleware (add white noise) implementation
//Somewhere in your codebase
const meeting = await DyteClient.init(...);
function lowPassFilter(audioContext) {
const bufferSize = 512;
let lastOut = 0.0;
const lowPassFilterProcessor = audioContext.createScriptProcessor(bufferSize, 1, 1);
lowPassFilterProcessor.onaudioprocess = function onaudioprocess(e) {
const input = e.inputBuffer.getChannelData(0);
const output = e.outputBuffer.getChannelData(0);
for (let i = 0; i < bufferSize; i += 1) {
output[i] = (input[i] + lastOut) / 2.0;
lastOut = output[i];
}
};
return lowPassFilterProcessor;
}
// Add audio middleware
meeting.self.addAudioMiddleware(lowPassFilter);
Sample audio middleware (low pass filter) implementation
Note: In case you are building an Audio Transcriptions middleware or any sort of middleware that doesn’t alter the original audio stream, please feed the output channel with whatever you get from inputChannel so that the audio can be sent to the next middleware. Otherwise, a blank audio buffer will be sent to the next middleware. This is done so that you can implement middlewares such as noise cancellation middlewares and have the ability to drop audio altogether if there is no foreground sound at all.
const inputData = e.inputBuffer.getChannelData(0);
const outputData = e.outputBuffer.getChannelData(0);
// Output to the buffer to not halt audio output
inputData.forEach((val, index) => {
outputData[index] = val;
});
A code block to pass audio data
Note: Safari doesn’t support canvas rendering & Audio Context manipulation for background tabs. Therefore, we do not support Safari, as of now. Google Chrome is recommended.
Where to next?
There is more to these Streams APIs. You can use these APIs to address some unique scenarios. For example: add a watermark on the video, put your logo within each video stream or perhaps add some branding. To help you understand how these APIs work, we have added a few more samples in https://github.com/dyte-in/streams-middleware-samples. We will keep releasing some cool samples with these APIs in near future.
Let us know how the streams API has helped you achieve your business goals. We would love to see the cool stuff that you have implemented using the streams API.
Till then, Hasta Luego, and Happy Coding.
If you haven’t heard about Dyte yet, head over to https://dyte.io to learn how we are revolutionizing live video calling through our SDKs and libraries and how you can get started quickly on your 10,000 free minutes which renew every month. If you have any questions, you can reach us at support@dyte.io or ask our developer community.